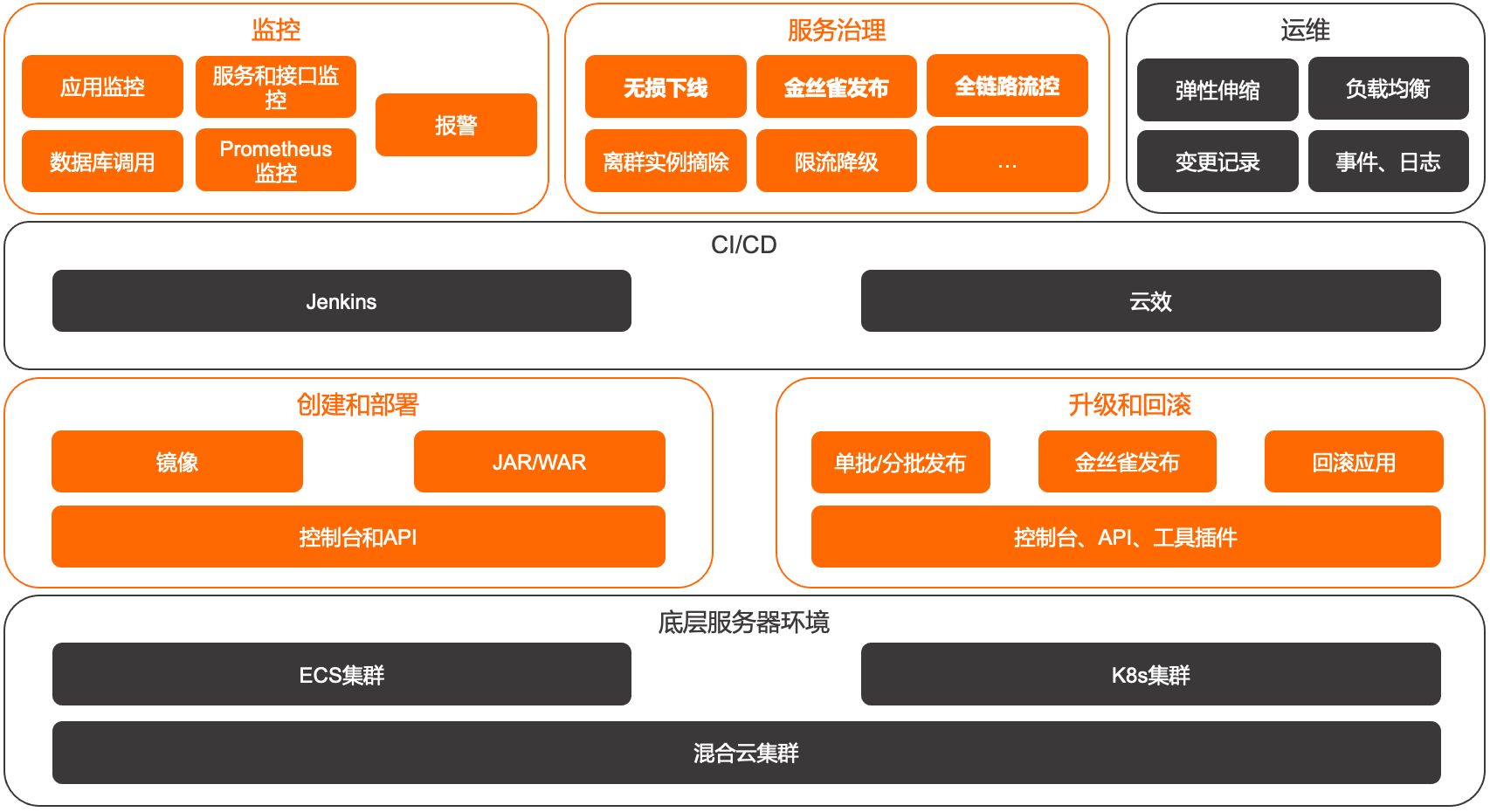
系统架构参考
企业级分布式应用服务EDAS
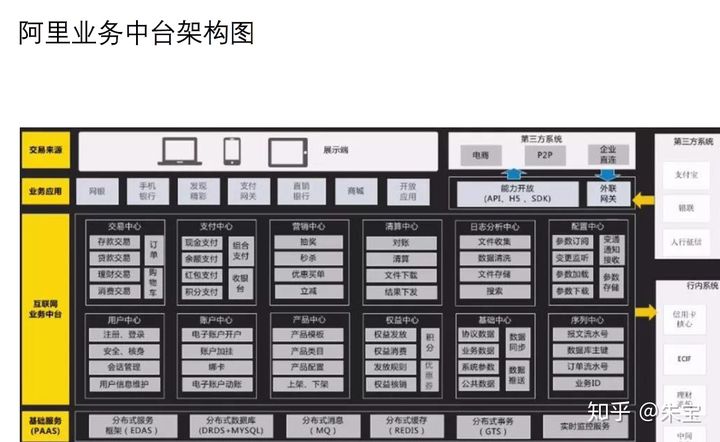
阿里中台架构图
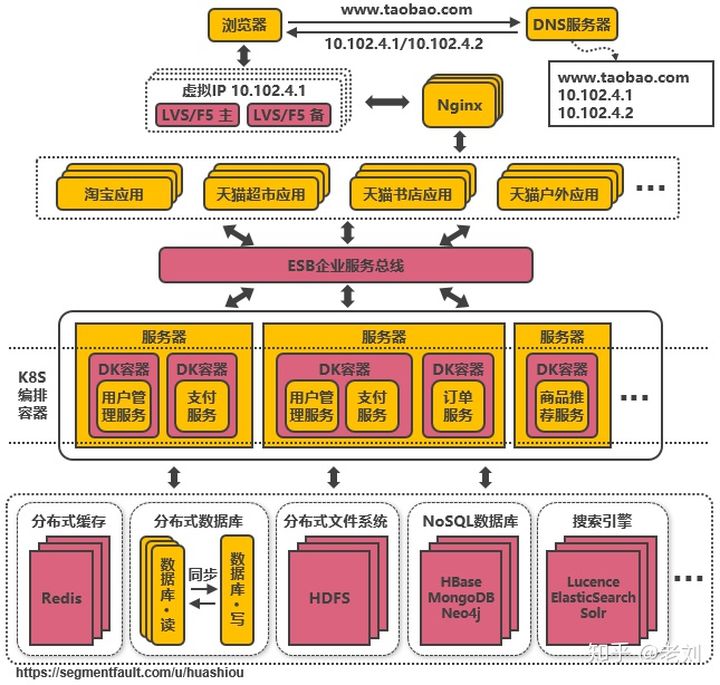
淘宝服务端高并发分布式架构
- 架构特点:负载均衡、正向代理和反向代理、分布式、高可用
- MPP数据库
- 使用LVS或F5来使多个Nginx负载均衡(可使用keepalived软件模拟出虚拟IP,然后把虚拟IP绑定到多台LVS服务器上)
- 通过DNS轮询实现机房间的负载均衡(系统可做到机房级别的水平扩展)
引入NoSQL数据库和搜索引擎等技术+
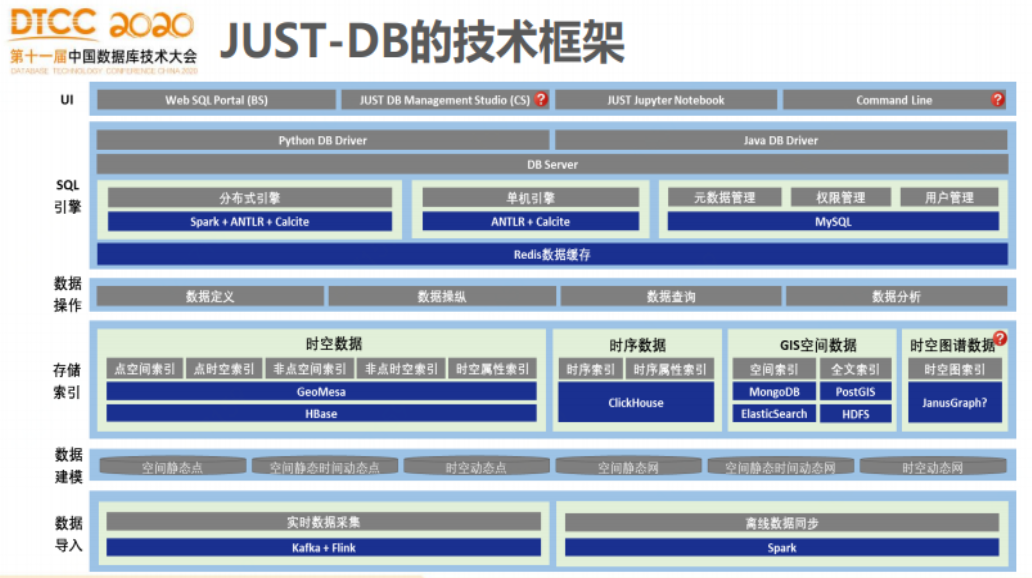
JUST-DB
云原生技术架构
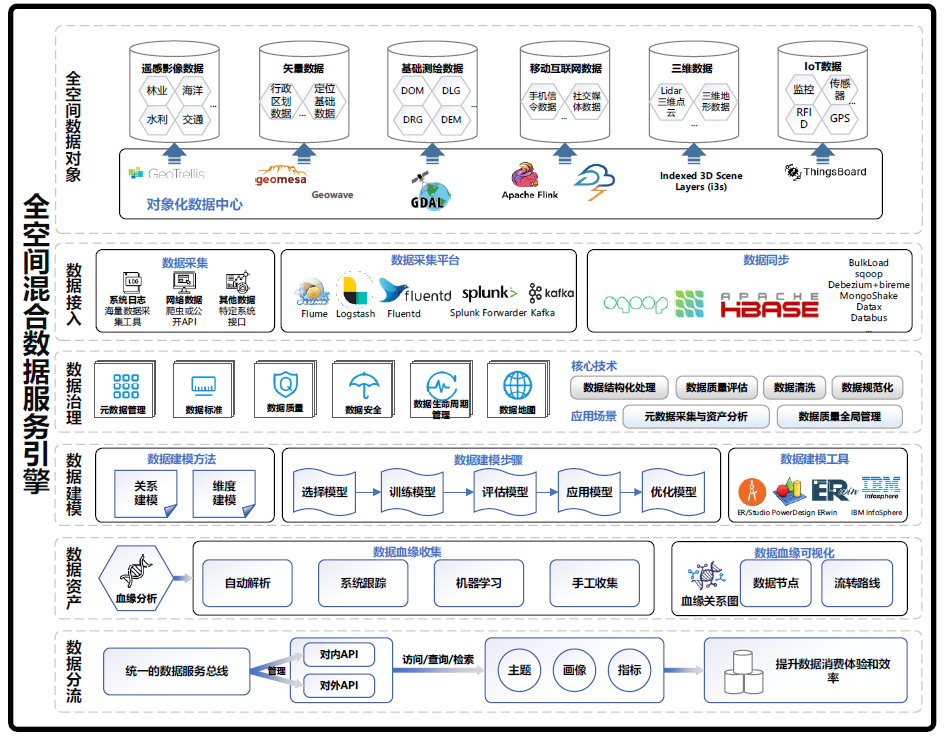
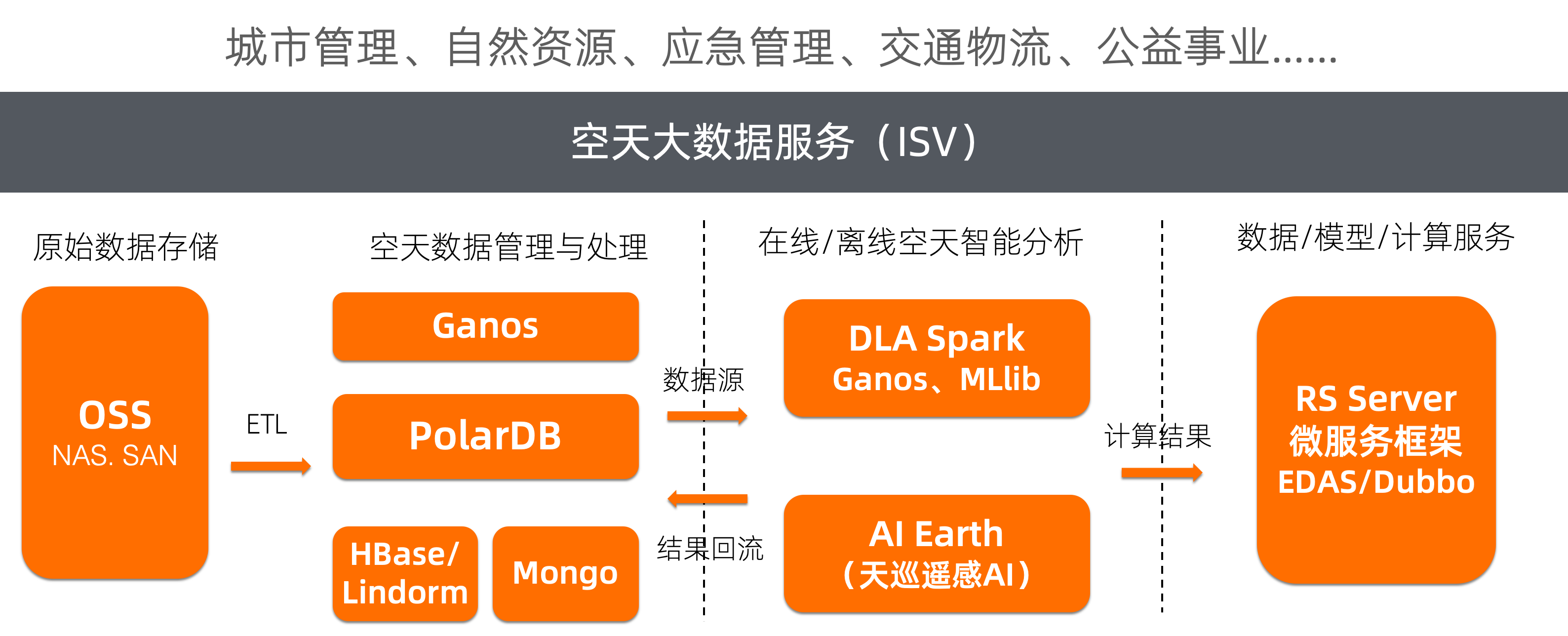
全空间混合数据服务引擎
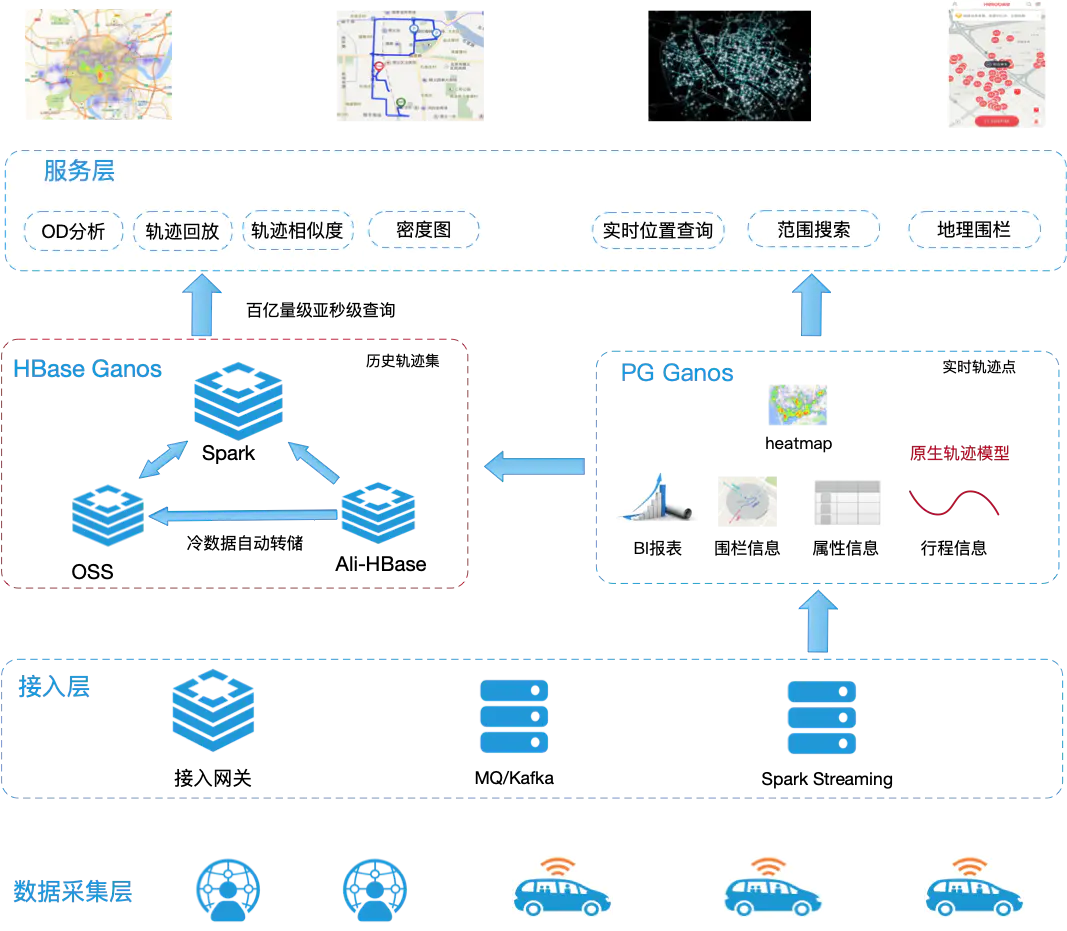
Ganos
Ganos是包含SQL + NoSQL云数据库的时空引擎。
- 公有云原生架构的空间、时空、遥感一体化NoSQL大数据引擎产品,开箱即用;
- PB级存储、高并发写入、百亿级时空查询秒级响应;
- 支持数据冷热分离存储和数据高效压缩算法,海量数据存储成本低;
- 与云上Spark无缝集成,快速搭建空间大数据仓库和空间大数据分析平台;
- 基于OGC标准设计,便于系统间的集成与互操作;
- 基于阿里云HBase、XPack专业运维,全托管方式,提供可靠稳定的服务。
Ganos中的时空模型
除了支持传统的几何模型、栅格模型和拓扑网络模型,还扩充支持了网格模型、时空轨迹模型以及点云模型。

PG Ganos
- 如何管理PB级遥感影像:PostgresSQL + Ganos + OSS
通过“PostgresSQL + Ganos + OSS”组合,可实现 PB级遥感影像的管理。源数据和部分金字塔数据可以存储在数据库内部,遥感原始数据存放在OOS中,由于OOS存储价格低廉,使得用户的使用成本也有所降低。
- 遥感影像注册(入库)
需要按照insertSQL语句直接写入到数据库,将OSS地址传给createrast接口即可。
- 矢量数据入库
主要依赖空间开源的工具,包括Ogr2ogr、shp2pgsql、QGIS、pg_dump/pg_restore等。
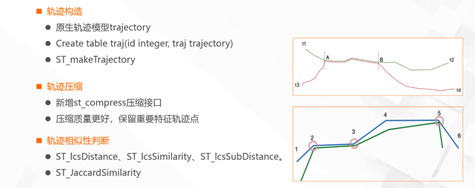
- PG Ganos如何管理轨迹数据
Ganos管理轨迹数据主要通过轨迹构造、轨迹压缩和轨迹相似性判断。
- Ganos与开源工具
Ganos无缝对接兼容PostGIS的各类GIS软件,显示和编辑包括GeoServer、QGIS、uDig、OpenJump等,PGAdmin4。
示例:某位置服务平台
示例:遥感大数据管理与智能服务平台
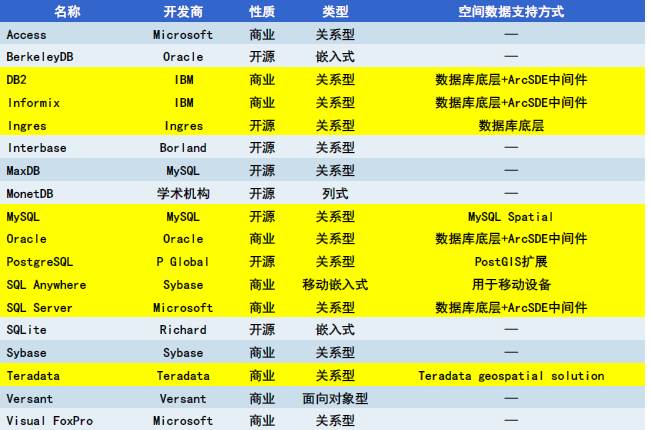
名词解释:
NoSQL
MPP (Massively Parallel Processing)大规模并行处理架构。比较流行的有Greenplum、TiDB、Postgresql XC、HAWQ等,商用的如南大通用的GBase、睿帆科技的雪球DB、华为的LibrA
LVS(Linux Virtual Server):本质上是一个软件。是一种集群(Cluster)技术,采用IP负载均衡技术和基于内容请求分发技术。
- VS/NAT 负载均衡策略:
- VS/TUN 负载均衡策略:
- VS/NAT 负载均衡策略:

- 链接
F5是一种负载均衡硬件,与LVS提供的能力类似,性能比LVS更高,但价格昂贵。
如对于海量文件存储,可通过分布式文件系统HDFS解决,对于key value类型的数据,可通过HBase和Redis等方案解决,对于全文检索场景,可通过搜索引擎如ElasticSearch解决,对于多维分析场景,可通过Kylin或Druid等方案解决。
geoTrellis:处理栅格数据。生成金字塔图层、渲染切片、GeoJson的序列化与反序列化
geoMesa:处理矢量数据。由locationtech开源的一套地理大数据处理工具套件。 GeoMesa目前支持的NoSQL数据库包括Accumulo、HBase、Google Bigtable和Cassandra等。
DLI:数据湖探索
DLA:数据湖分析
Apache Kylin™是一个开源的、分布式的分析型数据仓库。提供
Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的Hive表。其核心是预计算,计算结果存在HBase中。作为大数据分析神器,它也需要站在巨人的肩膀上,依赖
HDFS、MapReduce/Spark、Hive/Kafka、HBase等服务。Apache Flink并不提供自己的数据存储系统,但为Amazon Kinesis、Apache Kafka、Alluxio、HDFS、Apache Cassandra和Elasticsearch等系统提供了数据源和接收器。
Presto是一种用于大数据的高性能分布式SQL查询引擎。其架构允许用户查询各种数据源,如Hadoop、AWS S3、Alluxio、MySQL、Cassandra、Kafka和MongoDB。
Drill:Drill is an Apache open-source SQL query engine for Big Data exploration.
LSM-tree 最大的特点就是写入速度快,主要利用了磁盘的顺序写,pk掉了需要随机写入的 B-tree。关于磁盘的顺序和随机写可以参考:《硬盘的各种概念》
全时空信息系统架构设计
数据底层分类
数据库引擎
NewSQL 见文档-NewSQL主流数据库对比
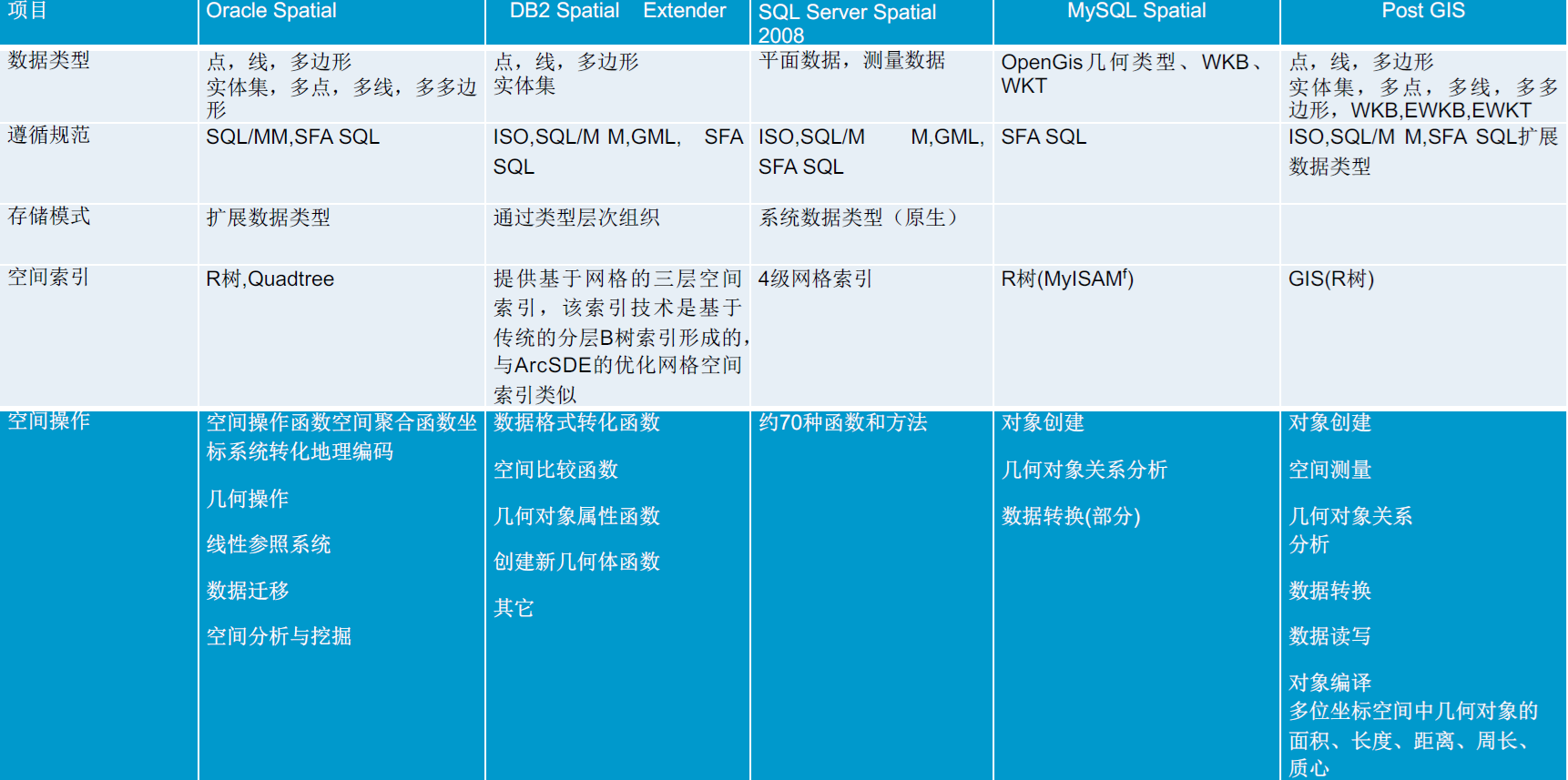
检索引擎
计算引擎
容器化、微服务、DevOps
可视化引擎
参考连接
1. 淘宝服务端高并发分布式架构演进之路
https://zhuanlan.zhihu.com/p/69999325
2. 微服务网关Zuul、Gateway、nginx的区别
https://www.jianshu.com/p/8d82c6c2e5ee
https://blog.csdn.net/lizz861109/article/details/103575186
3. Hive、Hbase、mysql的区别
https://zhuanlan.zhihu.com/p/137458844
4. 解惑图数据库!你知道什么是图数据库吗?
https://cloud.tencent.com/developer/article/1634337
5. 图数据库选型对比:HugeGraph、JanusGraph、Neo4j
https://blog.csdn.net/hellohiworld/article/details/104824764
6. JanusGraph/Neo4j/TigerGraph简单对比
目前TigerGraph的生态不是很全,编程api等能力也有一定限制
https://zhuanlan.zhihu.com/p/74424421
7. 全文搜索引擎 ElasticSearch 还是 Solr?
https://www.cnblogs.com/jajian/p/9801154.html
8. 9个基于Java的搜索引擎框架 转
https://cloud.tencent.com/developer/article/1184216?from=article.detail.1178714
9. 什么是CIM?究竟和BIM有什么关系?
https://zhuanlan.zhihu.com/p/359816845
10. BIM+GIS应用的八大挑战
https://blog.csdn.net/supermapsupport/article/details/95048023
11. HBase Ganos简介
https://www.jianshu.com/p/cad5467cc67d
12. 对比五款数据库,告诉你 NewSQL 的独到之处
https://www.techug.com/post/what-is-new-about-newsql.html
13. NewSQL究竟新在哪里?
http://oserror.com/distributed/newsql/